
AI 工厂:智能供应链的系统工程#
训练一个前沿大模型需要消耗一座小城市数月的用电量、数万亿词的文本数据、以及价值数亿美元的算力芯片。算力 (Compute Power)、算法 (Algorithms) 与数据 (Data)——这三大要素究竟如何协同运作?将 AI 系统比作一座以电力驱动的工厂,可以帮助我们看清整条供应链的全貌。
在这个类比中:
- 算力 (Compute Power) 本质上就是电力 (Electricity)。所有产生算力的硬件(GPU、CPU、TPU)都直接依赖于电能的供给。
- 算法 (Algorithms) 是工厂的引擎 (Engine)——即加工原材料的核心方法与技术(如 Transformers 或混合专家模型 MoE)。
- 数据 (Data) 则代表原材料 (Raw Materials)——即用于训练 AI 模型的海量信息流。
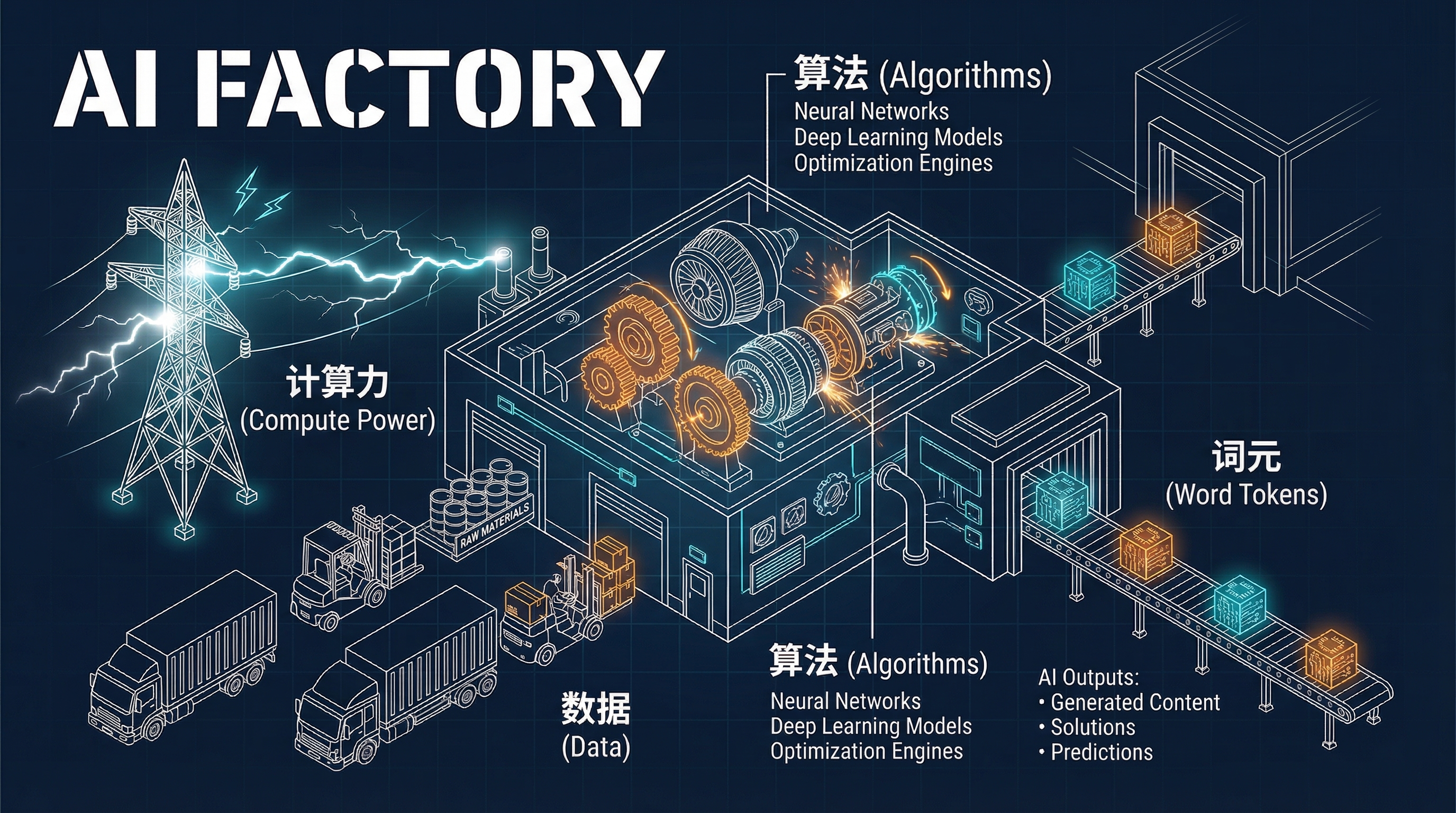
这座工厂的运作机制可以从三个维度来理解:基础设施层的数据中心 (Data Center)、生产层的模型训练 (Production),以及应用层的消费者视角 (Consumer)。
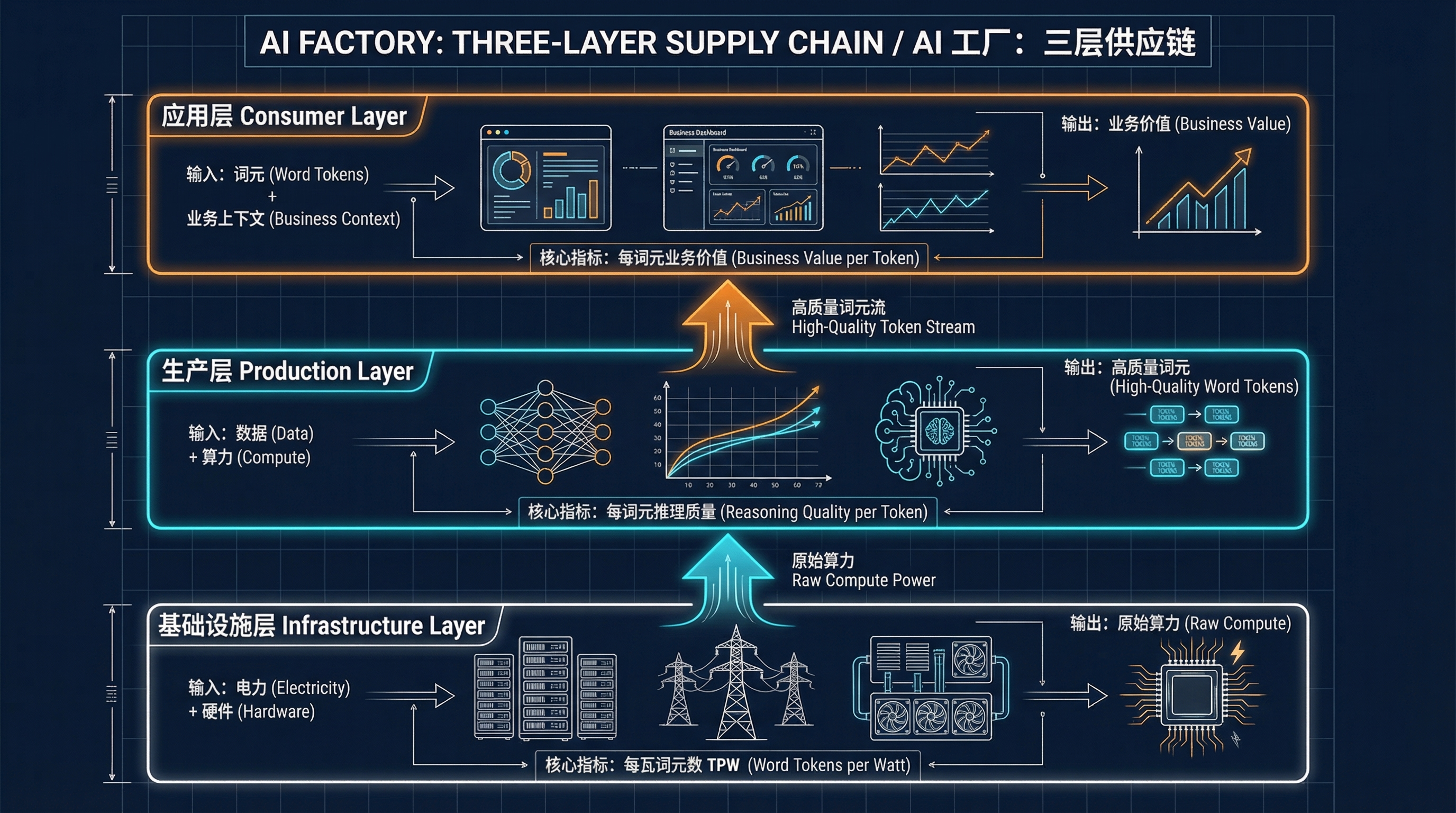
第一部分:数据中心视角(硬件与基础设施)#
在整个技术栈的最底层,是 AI 基础设施所面临的物理约束。算力并非取之不尽的虚拟资源,AI 数据中心的扩张受到电网负载、冷却效率以及物理空间的根本限制。
功耗墙与热管理约束#
在数据中心层面,这些设施更像是 AI 世界的“发电厂”。现代高端 GPU(如 NVIDIA Blackwell (B200))单颗芯片的功耗已超过 1,000 瓦特。当一个集群包含 10 万颗此类芯片时,主要的工程挑战将从软件转向热管理 (Thermal Management)。
许多现代 AI 工厂正从空气冷却转向芯片直接液冷 (Direct-to-Chip Liquid Cooling) 技术,以防止高密度 GPU 集群在全功率运行时发生物理熔毁。这也解释了为什么 AI 领域的巨头们正开始投资专用能源——他们正在从物理层面确保工厂的电力供应。
关键指标:每瓦特生成的词元数 (TPW)#
衡量该层效率的核心指标是每瓦特生成的词元数 (Word Tokens Generated Per Watt, TPW)。数据中心必须在有限的电力预算内,生产尽可能多的词元。量化 (Quantization) 技术(如将数据精度从 16 位降低到 4 位)本质上是尝试使用”更细的导线”来传输相同的信息——这虽然更高效,但需要精密的工程设计来避免信号损失(即精度下降)。
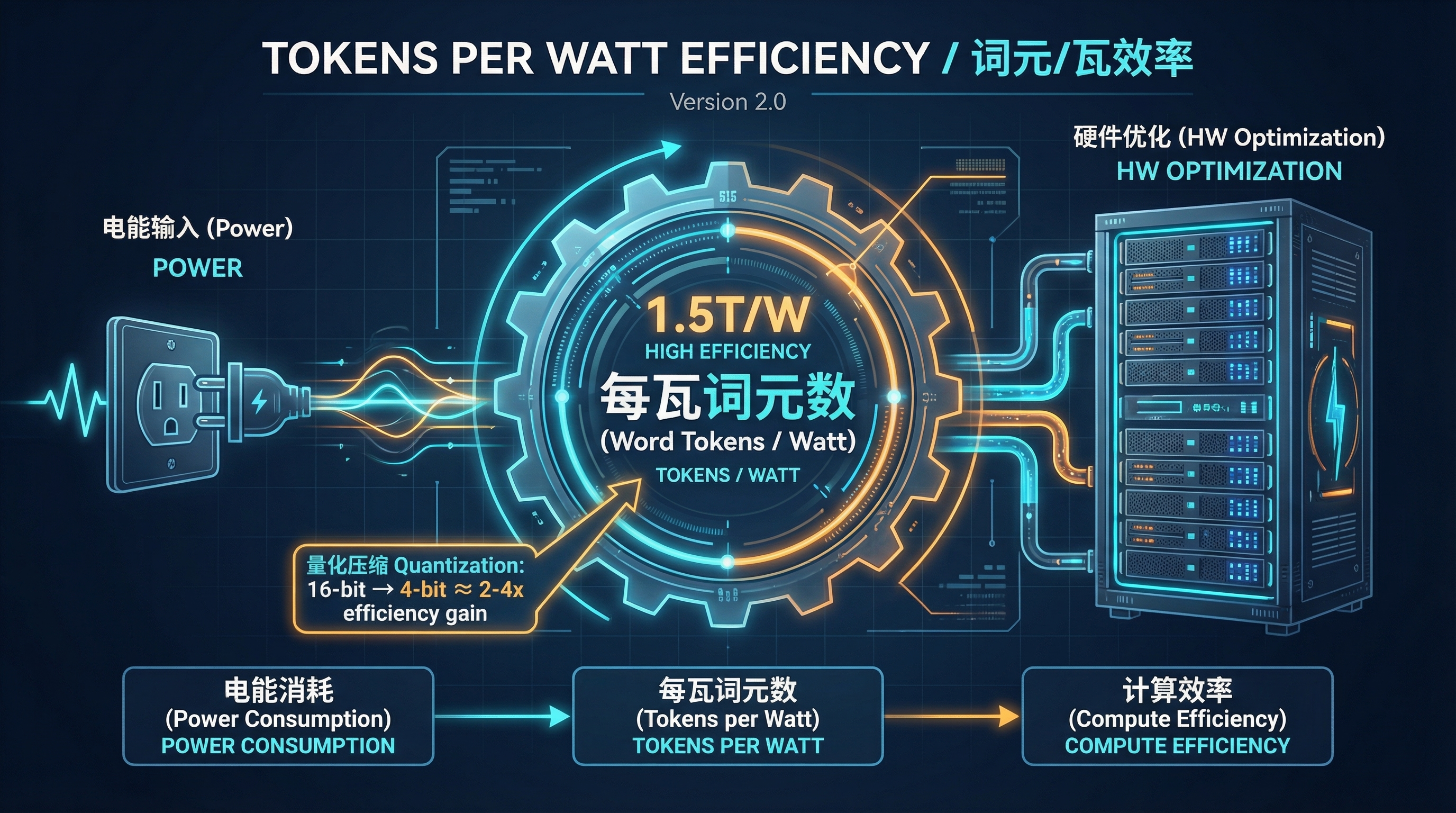
但单纯提高每瓦特词元产出还不够——如果每个词元承载的信息质量低下,再高的产量也是浪费。这就引出了生产层面的核心问题。
第二部分:AI 生产视角(算法与训练)#
跳出纯硬件层,我们来到了构建基座模型 (Foundation Models)(如 GPT 系列、Claude 系列或 Gemini 系列)所需的软件工程层面。在这里,关注点从原始的”数量”(每瓦特词元数)转向了每词元的推理质量 (Reasoning quality per token)——即单个词元能够承载多少准确、有用的信息。
架构效率:多引擎工厂#
不同的基座模型在两个主要维度上展开竞争,以提升词元质量:
- 算法调优 (Algorithmic Tuning)(引擎优化): 尽管 Transformer 仍是目前的标准引擎设计,但诸如混合专家模型 (MoE) 之类的新型架构如同一家拥有多条专业生产线的工厂:接到订单后,调度系统只启动对口的生产线,其余保持待机。这使得万亿参数的模型在推理时只需调用一小部分参数,大幅降低算力消耗。
- 数据质量 (Data Quality)(原材料纯度): 这涉及到了数据精炼厂 (Data Refinery) 的构建。随着互联网上高质量人类文本的枯竭,包括去重和质量过滤在内的“数据清洗”变得至关重要。此外,工厂正越来越多地利用合成数据 (Synthetic Data)——这形成了一个闭环回收系统,将上一代模型的高质量产出作为下一代模型的优质原材料。
质量控制:对齐技术 (Alignment)#
工厂的最后一道检验工序是对齐技术 (Alignment)——确保模型产出符合人类价值观和意图。早期的代表性方法是人类反馈强化学习 (RLHF),由人类标注员对模型输出进行评级;如今这一体系已扩展为包含 DPO(直接偏好优化)、RLAIF(AI 反馈强化学习) 等多种方法在内的综合质检流程。其核心目标始终如一:保证最终交付给客户的”成品”(即词元)是准确、安全且真正有用的。
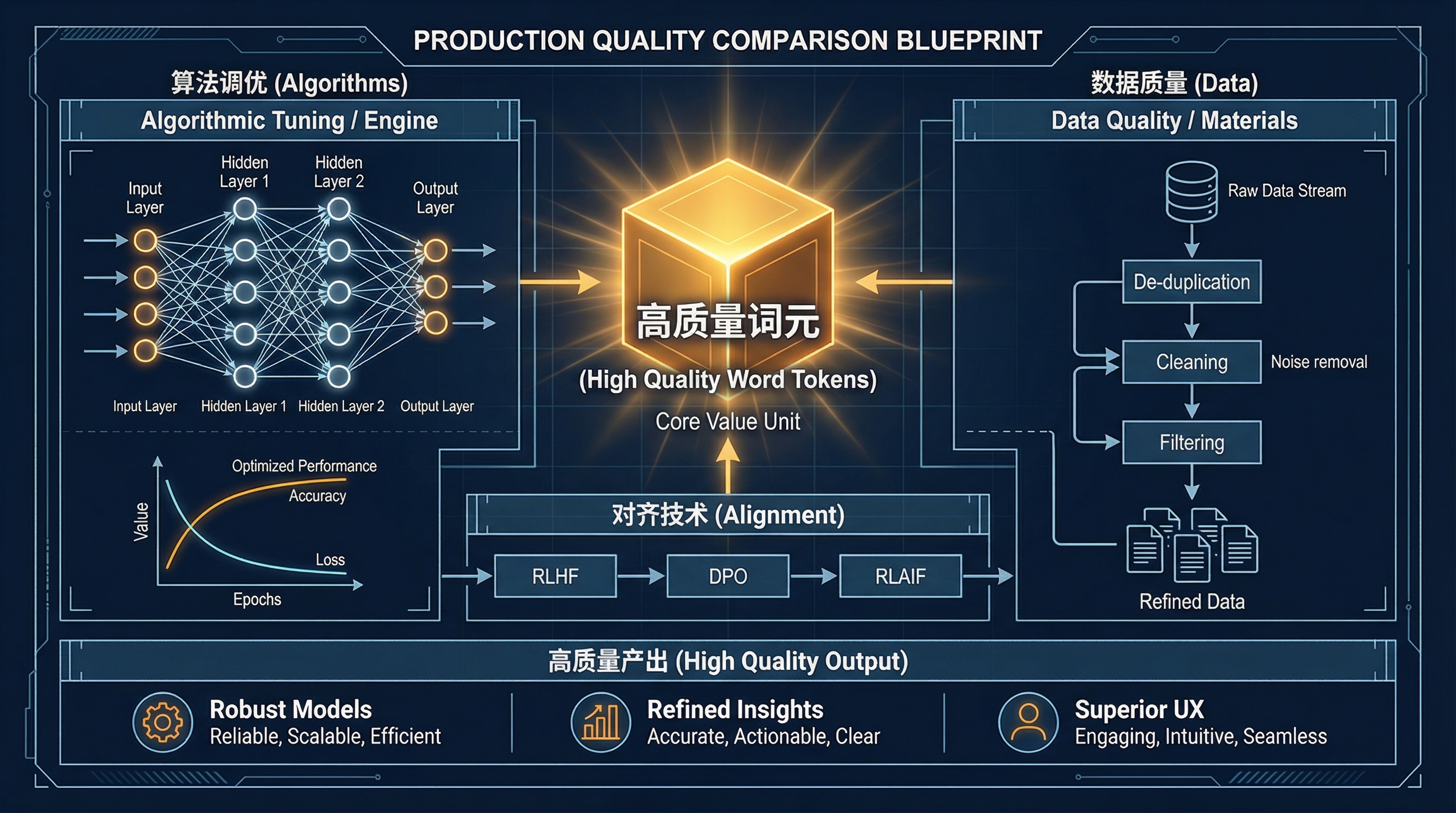
当生产层将词元的质量打磨到位,下一个问题随之而来:应用开发者如何高效地消费这些词元,并将其转化为真正的业务价值?
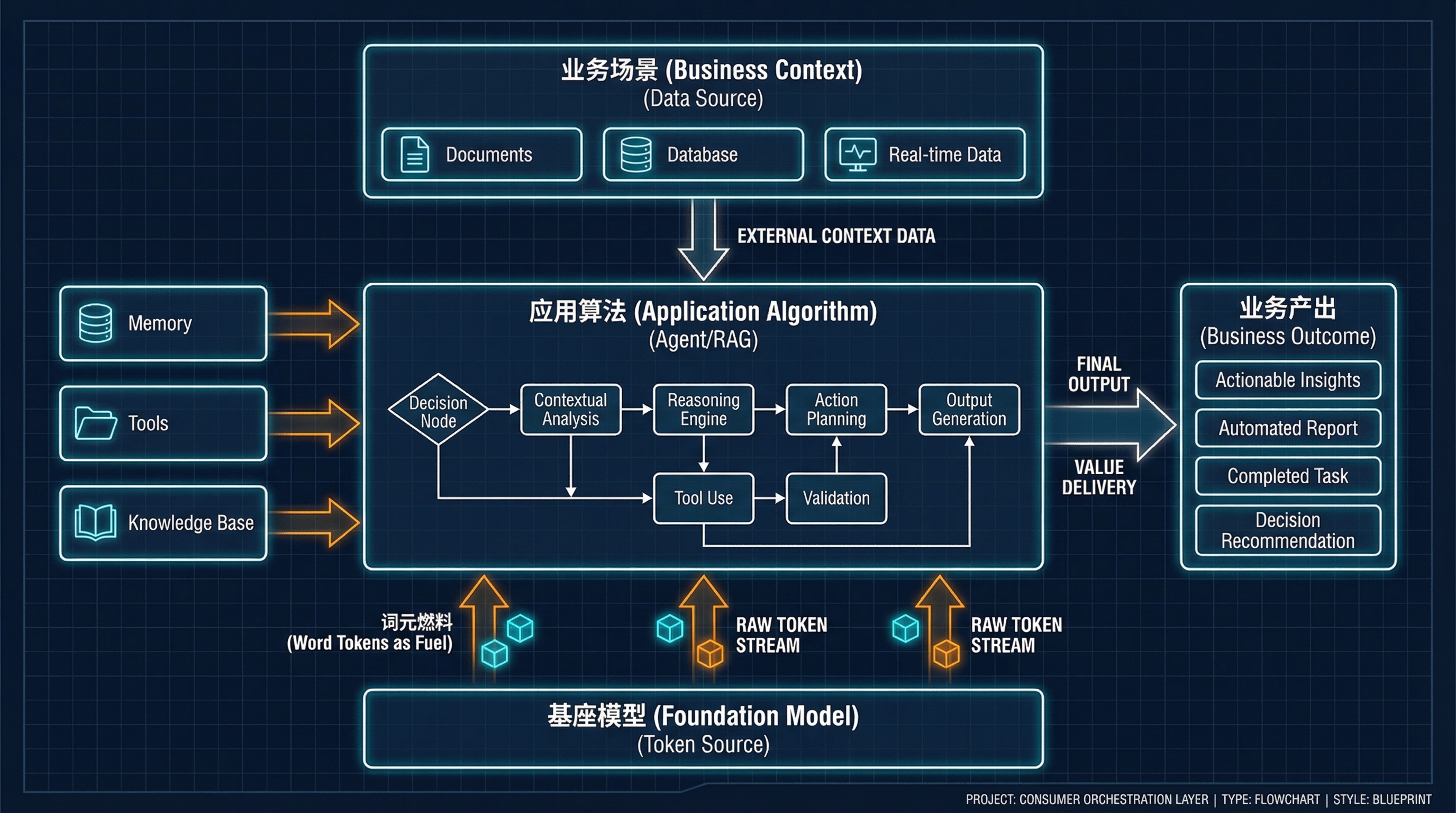
第三部分:消费者与应用视角(编排与代理)#
当我们从模型生产者的视角切换到应用开发者的视角时,同一种东西在供应链中扮演的角色发生了转变——这就像发电厂的”产品”(电力)对于下游制造商而言是”能源成本”一样。在应用层,生成的词元不再是最终产品,而是驱动业务逻辑的计费燃料;具体的业务上下文则成了需要加工的新一轮原材料。
词元即计费燃料#
对于应用开发者而言,词元不再是抽象的概念,而是字面意义上的成本——每一次 API 调用都在消耗真金白银的燃料预算。不必要的词元消耗不仅在烧钱,更在透支系统的延迟预算。
在应用层的工厂里:
- 词元 (Tokens) 就是你从电网(基座模型)中消耗的燃料。
- 业务上下文 (Business Context)(PDF 文档、用户日志、数据库)是必须输入系统的原材料。
- 应用“算法” 就是你的编排系统——包括 AI 代理 (Agents)、RAG 流水线以及思维链 (CoT) 推理。
编排的挑战#
这一层的工程师正在设计运行在“词元动力”之上的“智能家电”。检索增强生成 (RAG) 是一种在最后时刻将特定的“业务上下文”喂给模型的方法。而思维链 (CoT) 推理则类似于将机器设为“高性能模式”运行;它能产出更高质量的结果,但代价是显著提高的词元消耗率 (Token Burn Rate)。
结论:三重优化问题#
为了以最优的成本效益最大化业务能力,开发者和企业必须解决一个三重优化问题 (Triple Optimization Problem):
- 硬件效率 (Hardware Efficiency): 在基础设施层面,最大化单位成本/功耗下的词元产出。
- 模型效率 (Model Efficiency): 在生产层面,最大化单位词元所承载的智能度与可靠性。
- 应用效率 (Application Efficiency): 在消费者层面,最大化单位词元消耗所带来的业务价值。
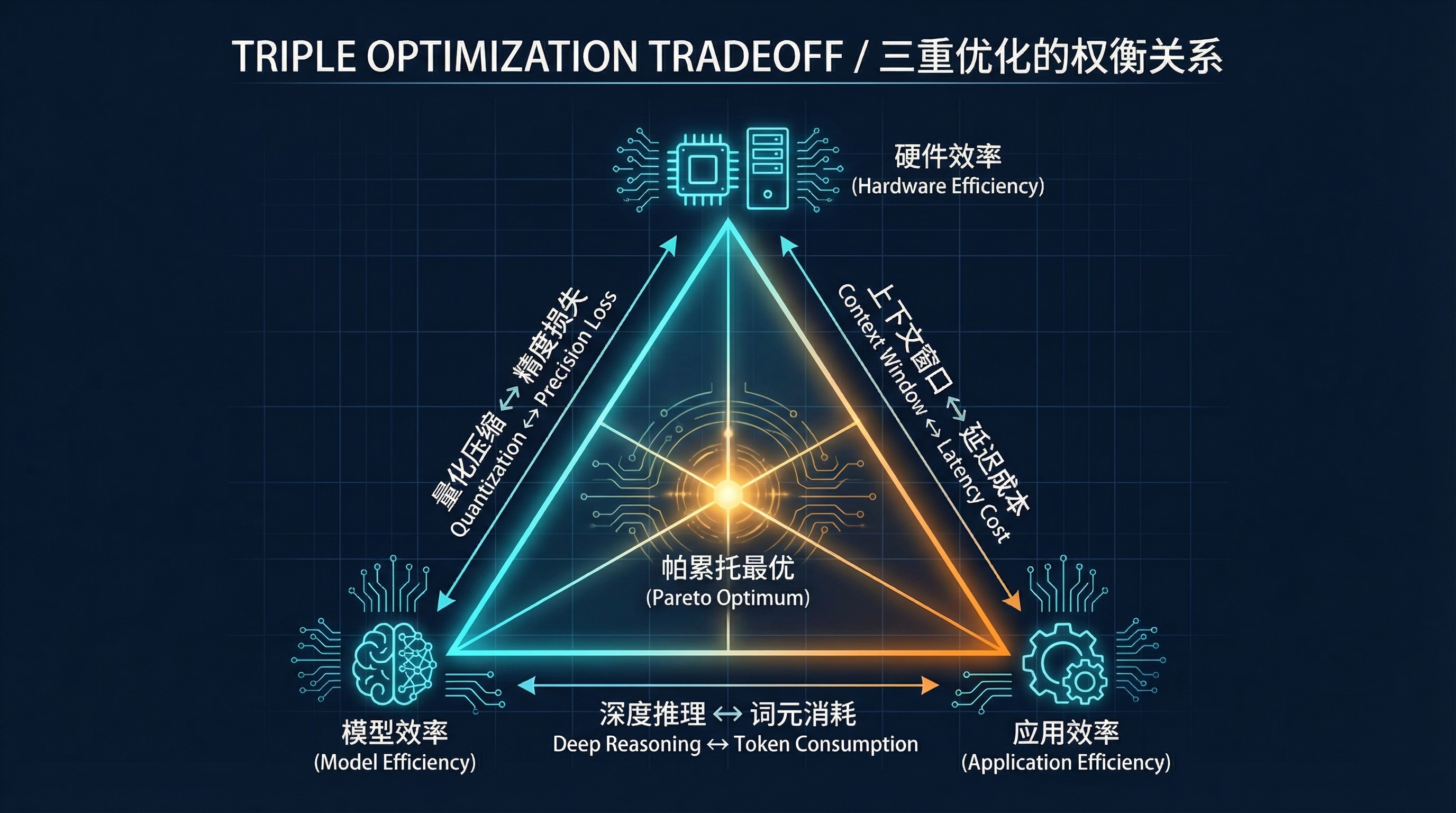
通过“AI 工厂”这一类比——从数据中心的物理局限到应用层的财务考量——工程师可以更清晰地把握技术脉络,从而构建出更高效、更强大且更具成本效益的 AI 系统。